

Budgeting your team’s code review capacity
AI generates code faster than your engineers can review it, and most teams haven’t adjusted for the gap.

👋 Hey, it’s Stephane. I help engineers become great engineering managers - whether you want to become one or are already leading a team.
Paid subscribers get 50 Notion Templates, The EM’s Field Guide, and access to the complete archive.

AI generates code faster than your engineers can review it, and most teams haven’t adjusted for the gap. Here’s how to treat reviewer attention as a constraint you actively manage.
If your team started using AI coding tools heavily this year, you’ve probably seen the same strange pattern I have. The team ships more, tickets move faster, and throughput dashboards look healthier than before. But at the same time, your senior engineers somehow look more tired, even though many of them are spending less time writing code.
A few months ago, one close friend of mine who’s a brilliant engineer told me: “I spend most of my day trying to decide whether I trust things.”
That statement explains a lot of what is happening right now.
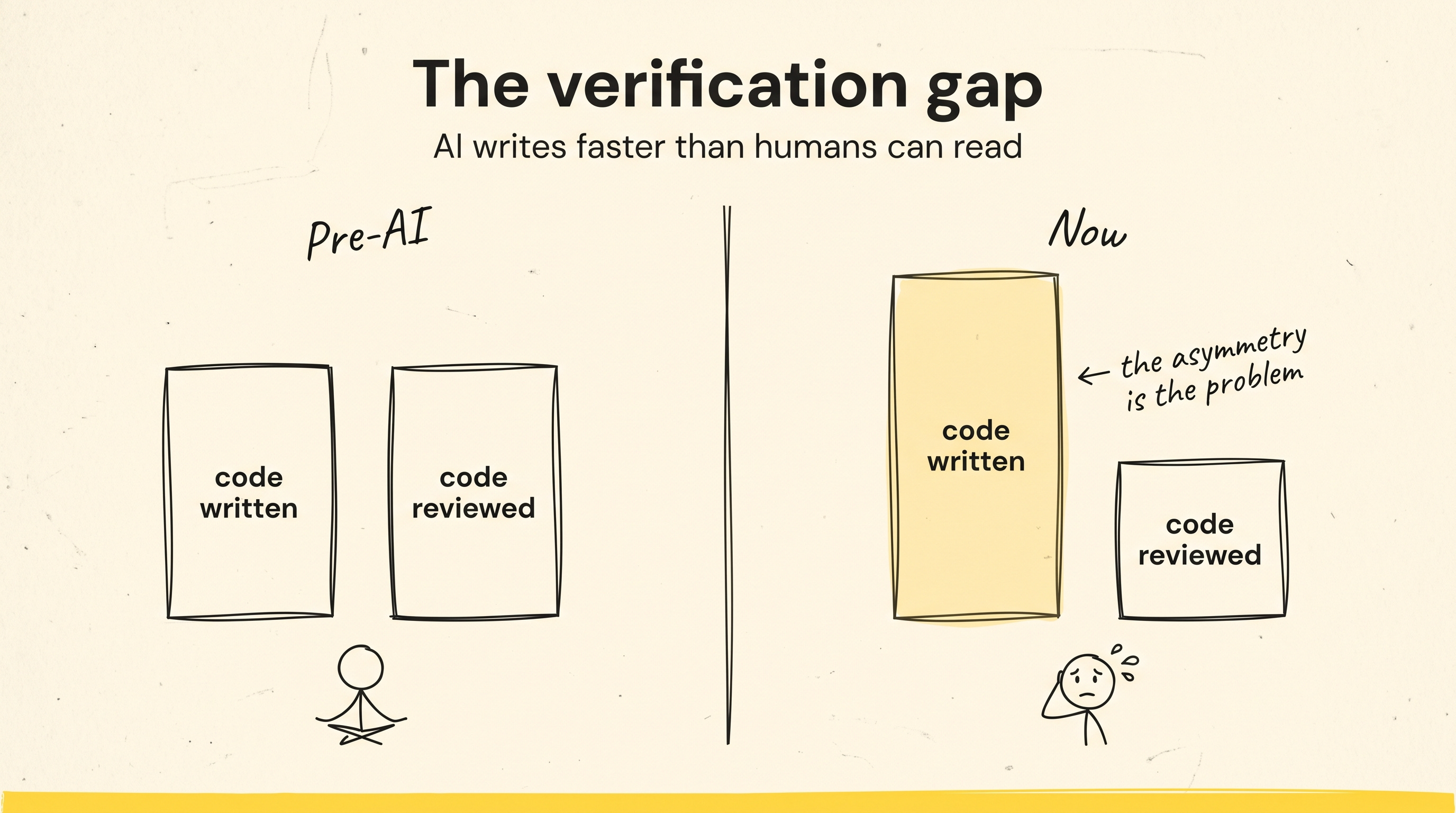
For years, writing code and reviewing code moved at roughly the same speed because humans did both. If somebody wanted to submit a huge pull request, they had to spend real effort building it first. AI broke that relationship. One engineer can generate an enormous amount of ok-looking code in a few hours, but the reviewer is still reading it at human speed.
Most teams haven’t adjusted for that change yet. They still treat reviewer attention as something that stretches forever, even though it has become one of the scarcest resources inside many organizations.
A strategic lever for reviewing code
Sponsored by JetBrains
This whole issue is about reviewer attention collapsing when there is a lot of AI-generated code. One thing that shapes how fast that happens is the language your team builds in.
A recent study from JetBrains looked at 320,000 developers and 28 million development cycles over 20 months. Kotlin development cycles were 15–20% shorter than comparable Java ones. More interestingly, Java codebases became 9–17% slower to work in over time, while Kotlin stayed roughly flat.
That matters even more now because we have so much AI-generated code. Human review speed has not scaled.
On JVM teams, Kotlin’s null safety and strong type system catch a huge class of “looks correct, fails later” bugs before a reviewer even sees the pull request. The result isn’t just better safety. It also makes AI-generated code easier to understand, reason about, and validate.
When code is clearer and easier to review, engineers can spend less time verifying implementation details and more time evaluating whether the solution itself is the right one. In an AI-heavy workflow, that translates directly into faster reviews, greater confidence, and more reliable software.

Thanks to JetBrains for sponsoring this newsletter!
Reviews needed suddenly exploded
Teams used to have a natural limit on how much code needed to be reviewed: writing it took time. That alone filtered out a lot of low-quality or half-thought-through work before reviewers ever saw it.
Mitchell Hashimoto described this well when talking about how agentic programming removed the natural effort-based backpressure that used to exist in software development. Generating code became dramatically cheaper, but checking whether that code is correct, maintainable, and safe still takes the same careful human attention it always did.
That asymmetry is the problem.
Jason Wei wrote about the asymmetry of verification in AI systems, and the idea maps perfectly here. Some things are much easier to create than to verify. AI-generated code falls directly into that category.
You can generate a convincing implementation in seconds, but understanding whether it actually makes sense still takes real concentration. Someone still needs to think through edge cases, read the logic carefully, understand the architecture choices, and decide whether this thing will behave strangely in production six months from now.
Open source projects are already seeing louder versions of this problem. OCaml maintainers recently closed a 13,000-line AI-generated pull request because nobody could justify the review effort required. The interesting part was that the discussion was not about code quality. It was about reviewer capacity.
Inside companies, the same thing happens. An AI-generated pull request can look very convincing until somebody spends time reading it. By the time reviewers realize a change is difficult to validate, they are already deep inside the cognitive work.
What overloaded reviewers actually do
Most teams think this is a workload problem. I don’t think it is. I think it’s an attention problem, and those are much harder to notice because overloaded reviewers still look productive from the outside.

The first thing that happens is review quality drops. Not because reviewers become lazy, but because humans adapt to volume. People skim more, trust tests more heavily, and assume somebody else probably already checked things carefully.
One engineer from CodeRabbit described this really well: eventually everyone in the chain starts assuming someone else probably did the deep verification work. A Sonar survey found that while 96% of developers don’t fully trust AI-generated code, fewer than half always verify it before committing it.
The second thing that happens is more dangerous over time. Teams slowly understand their own systems less.
Code review is not only about finding bugs. It’s one of the main ways technical understanding spreads through a team. When engineers review code carefully, they build mental models of how the system behaves, how different components connect, and where complexity is accumulating.
Saturated reviewers stop building those models because they no longer have enough time to deeply understand what they’re reading.
Simon Willison calls this cognitive debt: code can technically work while nobody deeply understands why it works. That debt usually appears during incidents, when someone gets paged and discovers the implementation behaves strangely under production load, but nobody can fully explain the assumptions behind it.
I wrote before about how fast-moving teams can slowly lose understanding of their own systems. AI makes that dynamic much sharper because code generation scales faster than comprehension does.
Fast shipping can hide shallow understanding.
The final effect is organizational. Your strongest engineers increasingly become invisible infrastructure for the rest of the company. They spend huge amounts of time reviewing AI-generated pull requests, catching subtle problems, preserving consistency, and preventing incidents, but very little of that work shows up properly in promotion conversations.
The engineer protecting the system often ends up looking less productive than the engineer rapidly generating visible output.
That made sense when writing code itself was the expensive part. It makes much less sense now.
Treat reviewer attention like a budget
There are people arguing that line-by-line code review itself is becoming unrealistic. Ankit Jain made this argument in a widely shared essay, saying that once output scales high enough, manual review eventually loses.
I think there’s truth in that argument. But I don’t think the answer is “stop reviewing”. I think the answer is becoming much more intentional about where reviewer attention gets spent.
The biggest mistake teams make right now is pretending reviewer capacity is infinite when it clearly isn’t.
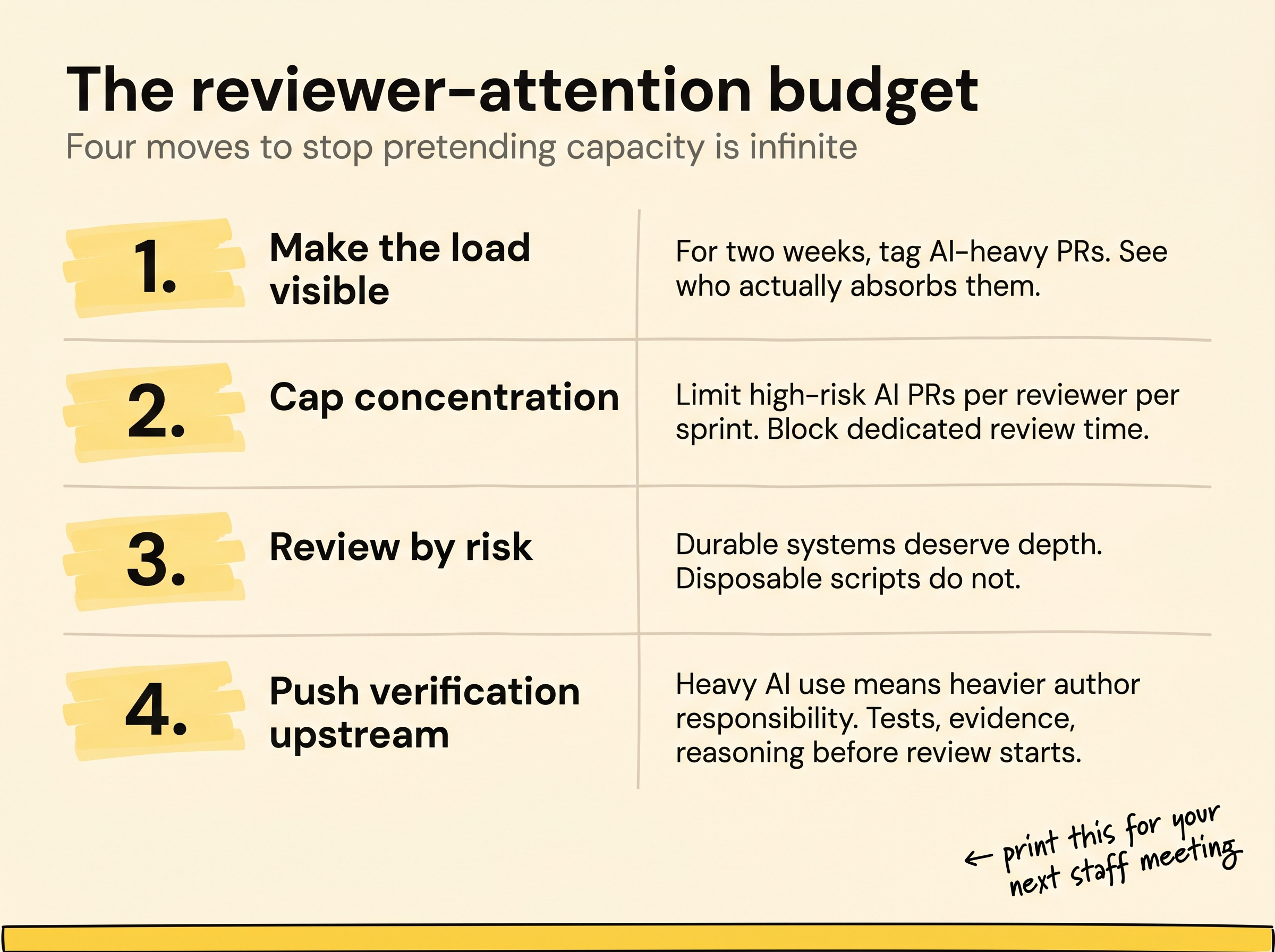
The first thing I’d recommend is making the concentration visible. For a couple of weeks, tag pull requests that are heavily AI-generated and look at who ends up reviewing them. Most teams quickly discover the same pattern: one or two senior engineers absorb most of the difficult verification work.
That concentration is the bottleneck.
The 2025 DORA report moved away from universal benchmarks for exactly this reason. Different teams have different constraints. You need to understand yours before you try fixing it.
The second thing is putting explicit limits on review load. At some point, people stop reviewing carefully because they simply cannot sustain that level of concentration every day.
Limit how many high-risk AI-generated pull requests one reviewer handles in a sprint. Create dedicated review blocks instead of constant interruptions.
The third thing is reviewing based on risk. Charity Majors talks about durable versus disposable code, and I think that distinction becomes very useful here. Authentication systems deserve deep understanding. A temporary internal migration script probably doesn’t.
The mistake is pretending every pull request deserves identical attention while reviewer capacity is already stretched thin.
The fourth thing is pushing more verification responsibility back toward the author. If somebody uses AI heavily to generate code, they should also carry more responsibility for proving the implementation works before review even starts. Good tests, clear reasoning, reproducible validation, and evidence the implementation behaves correctly matter much more now than they used to.
Reviewing AI-generated code is becoming a real senior engineering responsibility, but promotion systems barely acknowledge it. I wrote before about how some of the work holding teams together stays invisible, and verification work absolutely belongs in that category now.
If you don’t explicitly reward it, your strongest reviewers will eventually realize the smart career move is to stop reviewing carefully.
Where this leaves engineering leaders
The verification tax isn’t some future problem. Many teams are already paying it.
The reason it catches organizations off guard is that dashboards still show good news while reviewer capacity is collapsing underneath them. Throughput increases, but understanding spreads more slowly, review quality drops under pressure, and senior engineers spend larger parts of their week validating work they didn’t write and often can’t easily trust.
You do not need a massive reorganization to respond to this. Most teams probably just need to see where review load concentrates, put limits on what any one person absorbs, and start treating verification work as real engineering leverage instead of invisible maintenance work.
The real bottleneck in many organizations is no longer code generation speed. It’s reviewing that code that they’ll have to maintain.
If you enjoyed this article, consider subscribing to get:
✉️ Free: 1 original post every Tuesday, my favourite posts of the week every Sunday + 10 Notion Templates for Engineering Managers
🔒 Paid: Full archive + 50+ EM templates & playbooks + The EM Field Guide
See you in the next one,
~ Stephane