

On measuring engineers as individuals
Why the team is the only honest unit.

👋 Hey, it’s Stephane. I help engineers become great engineering managers - whether you want to become one or are already leading a team.
Paid subscribers get 50 Notion Templates, The EM’s Field Guide, and access to the complete archive.

A few weeks ago I was part of a discussion between experienced engineering managers.
One person shared something that really stuck with me. His company had started measuring every engineer with individual productivity metrics. A few months later, the engineers everyone relied on became less helpful. They stopped jumping into tricky debugging sessions. They stopped mentoring junior engineers and helping others unless they absolutely had to.
Not because they cared less. but because every minute spent helping someone else made their own numbers look worse.
Once people realized what was being measured, they changed what they spent their time on.
They simply optimized for what was being measured.
The engineer who stopped helping was rational.
He was the best mentor on the team and the person who knew the codebase best, so naturally he spent most of his day pairing and unblocking other people. The problem is that only one person gets to make the commit. He quickly realised that he was not getting the recognition for the work he was doing. So he stopped.
He went heads-down on his own tickets, his numbers recovered, and the team lost the one person who made everyone else faster. By the time anyone connected the dots, he was already interviewing elsewhere.
Individual productivity metrics measure what one person produces, and the most valuable engineering work is the work that helps other people produce.
I’ve written before about how your team’s throughput is lying to you and what actually happens when you try measuring developer productivity. This is the sharper version of both. The problem is not just tracking misleading numbers.
Your stupid metrics go up
This is why leaders miss it until it’s too late.
When you introduce individual output metrics, the numbers usually improve in the first quarter. Of course they do. Your engineers stop “wasting” time on work that doesn’t count, and they pour those hours into their own visible output. PR counts rise. Tickets close faster. The chart goes up and to the right.
So leadership reads it as proof that these metric have a positive impact.
What these metrics can’t show is that the rising line and the collapsing collaboration are the same event. The output goes up because the helping went down. You’re not necessarily watching a team get more productive. You might be watching it cannibalize the invisible work that kept it healthy.
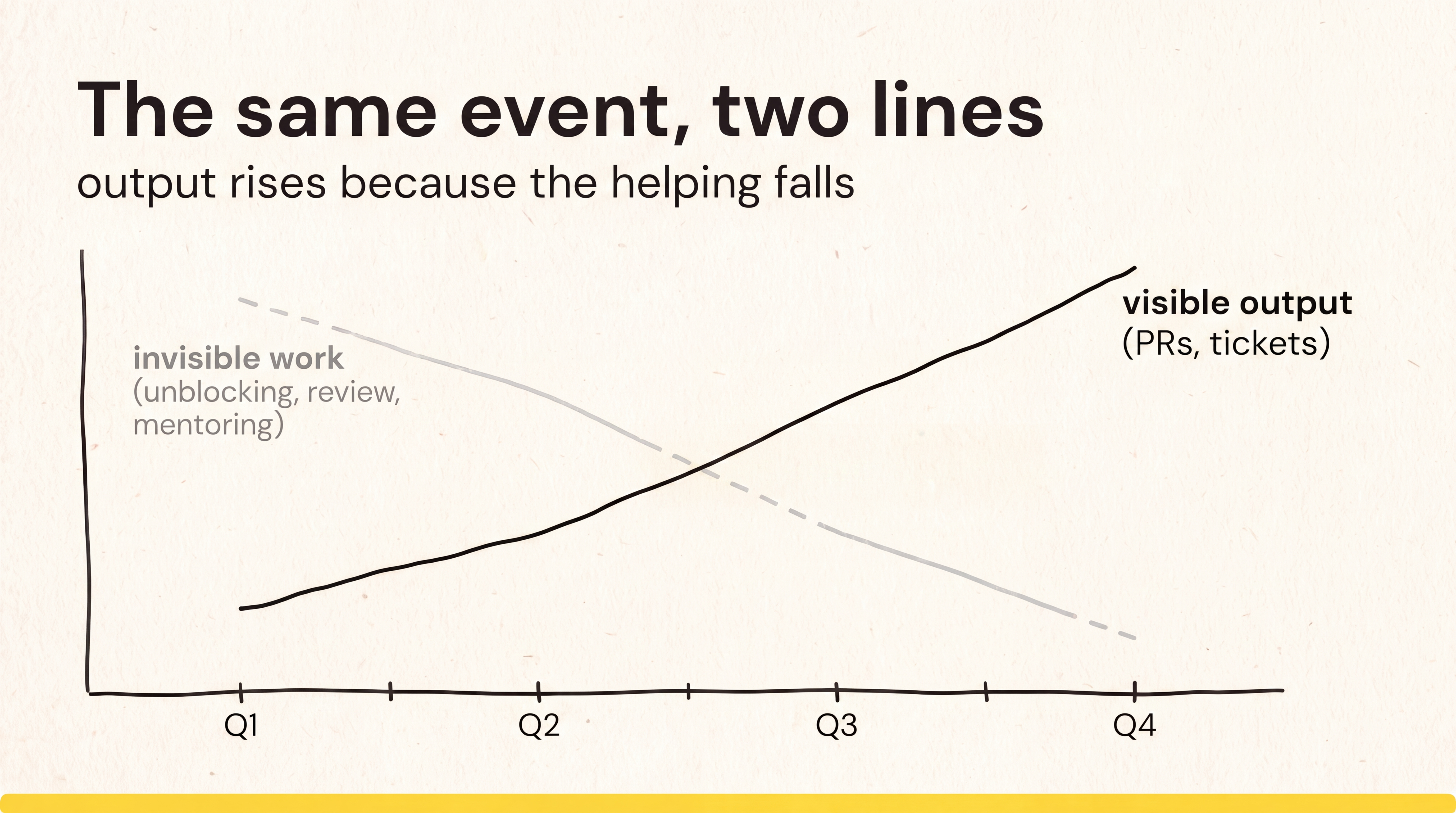
By the time the damage is legible, it shows up as things a dashboard doesn’t track. A senior leaves. An incident that should’ve taken an hour takes a whole day because nobody does root cause analysis anymore. Onboarding doubles because no one puts time into mentor.
When the bus factor catches up with you
Sponsored by Palark
The failure mode this whole issue describes - the one person who knew the system leaves, and the next incident drags on for a day - is exactly the gap Palark just built a product for.
Maintaining infrastructure and need extra hands to handle urgent incidents? DevOps insurance is a new B2B offering that delivers 24/7 peace of mind at low fees.

Palark, a holistic DevOps and SRE agency from Germany, just launched an affordable support service that works like a fire brigade for your cloud or server infra.
Similar to health or car insurance, DevOps insurance offers subscription plans with reasonable monthly fees and prompt assistance in case of infrastructure emergencies. It’s a perfect fit for:
small teams with no dedicated SRE or a bus factor in operations
cutting costs when infra “just works”
unexpected failures in complicated cloud/server services
Thanks to Palark for sponsoring this newsletter!
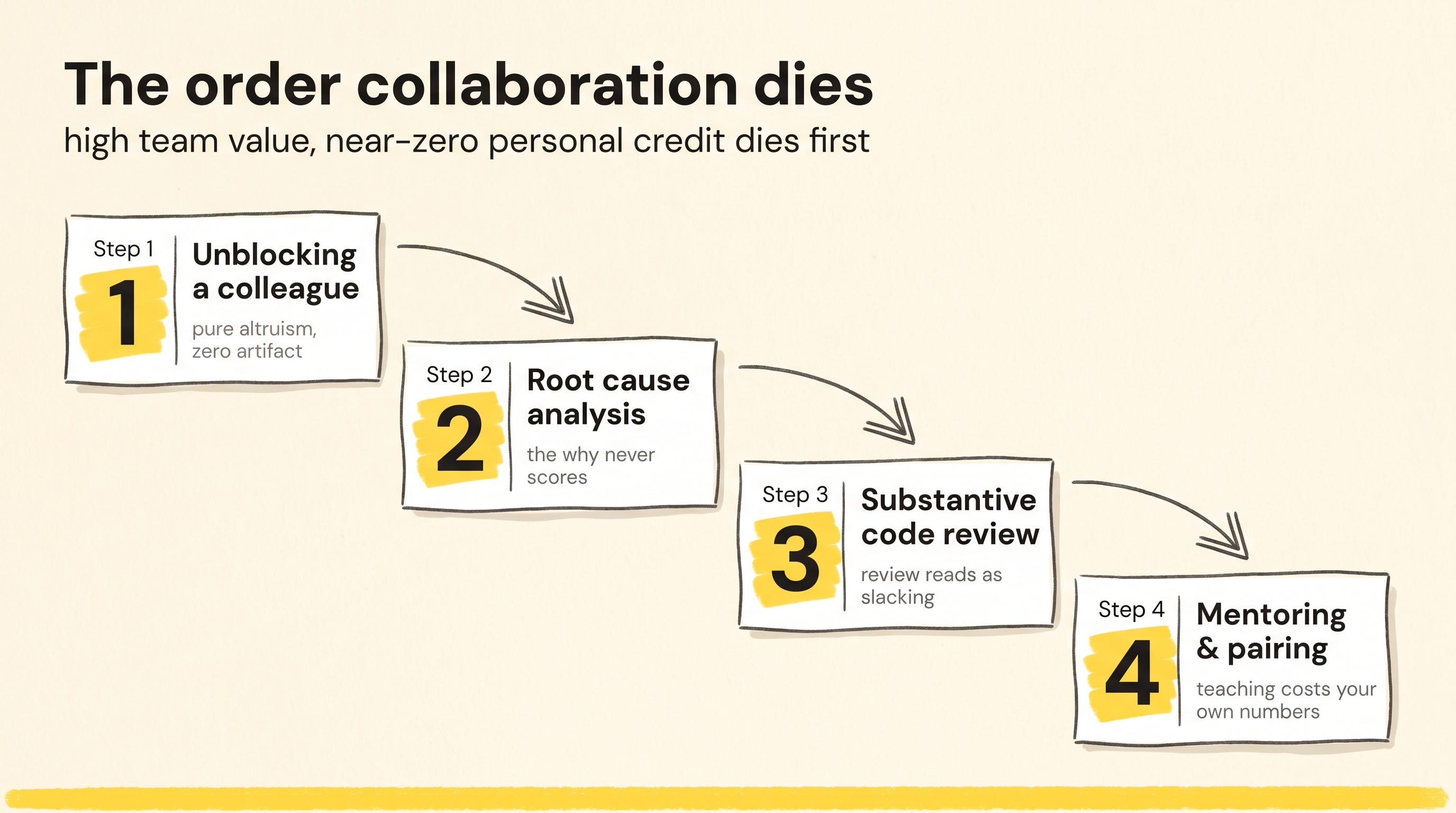
The behaviors die in a predictable order
Collaborative work doesn’t collapse all at once. It dies in sequence.
Rank each behavior by a simple ratio: how much it helps the team, divided by how much personal credit it earns. The work with high team value and near-zero personal credit dies first, because it’s the easiest sacrifice to justify when you’re being measured as an individual.
First to go: unblocking a colleague. It’s pure altruism. There’s no artifact, no commit with your name, or any relevant metric. The moment your time is being counted, the rational move is to stop helping and let people figure it out themselves. This is the same dynamic behind why 51% of devs stopped asking their teammates and ask AI instead. When asking costs the asker and helping costs the helper, both sides retreat.
Second: root cause analysis. Fixing a bug counts. Understanding why it happened does not. Deep investigation tends to surface more bugs that you’re now on the hook for. With ticket-closing metrics you have “little incentive to do more than the bare minimum to close tickets”.
Third: substantive code review. Real review takes time you can’t log against a story or a defect, so it reads as slacking. So review degrades into rubber-stamp approvals. It gets worse when the metric is dumber than that. At one large company, engineers were judged partly on iterations per review, and averaging more than two round-trips per change marked you as “sloppy” and put you on the chopping block. Thorough review became a firing risk. I’ve written about how to budget your team’s code review capacity, but no budget survives a metric that punishes the reviewer for caring.
Fourth: mentoring and pairing. This one is social and people feel bad abandoning it. But every hour you spend teaching is an hour subtracted from your own visible numbers. Eventually even the generous engineers stop. “Who has time to mentor junior colleagues when you gotta bump your LoC count for the quarter?”
Then the vacuum fills with gaming. People cherry-pick the easy tickets, split one change into five tiny PRs, inflate tasks, and write verbose code to look good on the stupid metrics.
This is structural
The objection I always hear at this point is “we’ll just be careful about which metrics we pick”. That doesn’t work, and there’s 50 years of research saying why.
Most people know Goodhart’s Law: when a measure becomes a target, it stops being a good measure. The version that matters here is what the researchers call the adversarial variant. Once people know the proxy is the target, gaming isn’t a risk you might avoid with a smarter metric. It’s a guarantee. There’s no individual metric careful enough to survive being tied to someone’s review.
I prefer Campbell’s Law, from 1976, because it names a second failure. The metric gets corrupted and the underlying work degrades. Campbell’s own example was an employment office: measure it on cases handled, and staff cherry-pick the easy placements while abandoning the people who most need help. Swap “cases” for “tickets” and you’ve described your engineering org.
Kent Beck in his response to McKinsey: “If you choose to create incentives around measures, know that you will never again receive accurate data.” The tighter you couple the metric to consequences, the less true your data becomes.
All that being said, the question naturally becomes what to measure instead.
Here’s what I personally track at the team versus the individual level:
